
이 글은 ByteByteGo에 기재된 'How Facebook served billions of requests per second Using Memchaced' 를 번역한 글입니다. 잘못 번역된 문장이나, 매끄럽지 못한 번역 내용이 있다면 댓글 부탁드립니다.
Facebook 규모의 소셜 네트워크를 운영하기위해서는 두 가지 절대적인 진실이 있다.
- 첫째, 서버가 멈춰서는 안된다.
- 둘째, 서버가 느려지면 안된다.
이 두 가지의 요소는 사람들이 소셜 네트워크를 계속 사용할지말지 여부를 결정한다.
사용자들이 연결되어있기 때문에 몇 명의 사람만 떠나더라도, 전체 사용자 기반에 영향을 미친다. 대부분의 사람들은 친구나 친척들이 온라인에 있고, 도미노 효과가 있기 때문에 온라인에 있다. 한 사용자가 이슈로 인해 이탈하게 된다면, 다른 사용자들도 이탈할 가능성이 있다.
Facebook은 인기때문에 이런 문제들을 일찍부터 처리해야했다. 어느 순간부터 수백만 명의 사람들이 전세계에 걸쳐 Facebook에 접속하고 있었다.
이는, 소프트웨어 디자인 측면에서 보았을 때 몇가지 중요한 필요 조건들을 뜻한다.
- Facebook은 실시간 통신을 지원해야한다.
- 즉석에서 콘텐츠 집계 기능을 구축해야한다.
- 수십억건의 사용자 요청을 처리할 수 있는 규모로 확장할 수 있어야 한다.
- 여러 지리적 위치에 걸쳐 수조 개의 항목을 저장할 수 있어야 한다.
이 목표들을 달성하기 위해선 Facebook은 Memcached의 오픈소스 버전을 채택하고, 이를 개선하여 분산형 key value 저장소를 구축했다. 이 향상된 버전은 Memcahce로 알려져있다. 이 글에서는 Facebook이 초당 수십억개의 요청을 처리하기 위해 memcached 확장에 대한 여러 챌린지들을 어떻게 해결했는지 살펴볼 것이다.
Memcached 소개
Memcached는 인메모리 key value 저장소로, set, get, delete과 같은 간단한 연산을 제공한다. 오픈소스 버전은 단일 머신 인메모리 해시 테이블을 제공했다. Facebook 엔지니어들은 이 버전을 기본 구성 요소로 채택하여 Memcache라는 분산형 key value 저장소를 만들었다.
즉, Memcached는 소스 코드 또는 바이너리인 반면, Memcache는 그 뒤에 있는 분산 시스템을 의미한다. 기술적으로, Facebook은 크게 두 가지 방법으로 Memcache를 사용했다.
Query Cache
query cache의 역할은 주요 진실 공급원(source-of-truth) 데이터베이스들의 부하를 줄여주는 것이다. Facebook은 Memcache를 수요 가득한 look-aside 캐시로 사용했다. cache-aside 패턴이라고도 들어봤을 것이다. 아래 다이어그램은 look-aside 캐시 패턴이 read와 write path에서 어떻게 동작하는지 보여준다.

Read path는 On-demand에 따라 채워지는 캐시를 활용한다. 이는 클라이언트가 명시적으로 요청할 때만 데이터가 캐시로 로드된다는 뜻이다. 요청을 제공하기 전에, 클라이언트는 캐시를 먼저 확인한다. 만약, 원하는 데이터를 캐시에서 찾지 못했다면 (a cache miss) 클라이언트는 데이터베이스로부터 데이터를 받고, 캐시를 업데이트한다.
Write path는 데이터를 업데이트하는데 조금 더 흥미로운 접근 방식을 취한다. 데이터베이스에 특정 키가 업데이트되면, 시스템은 캐시에 있는 해당 값을 바로 업데이트하지 않는다. 대신 해당 키에 대한 데이터를 캐시에서 완전히 제거한다. 이 프로세스는 캐시 무효화(cache invalidation)이라고 한다.
캐시 항목을 무효화함으로써, 해당 키에 대한 데이터를 클라이언트가 다음번에 요청할 때 캐시 미스가 발생하고, 데이터베이스에서 가장 최신 값을 직접 검색하도록 강제한다. 이 접근 방법은 캐시와 데이터베이스간의 데이터 일관성(data consistency)을 유지할 수 있도록 도와준다.
Generic Cache
Facebook은 Memcache를 일반적인 목적의 key-value 저장소로 활용한다. 이를 통해 조직 내 다양한 팀이 Memcache를 사용하여 계산 비용이 많이 드는 ML 알고리즘에서 생성된 사전 계산 결과를 저장할 수 있다. 사전 계산된 ML 결과들을 저장함으로써, 다른 애플리케이션들이 필요할 때마다 빠르고 쉽게 접근할 수 있다.
이 접근 방식은 향상된 퍼포먼스와 자원 최적화 같은 여러 이점을 제공한다.
Facebook의 고급 아키텍처
Facbook의 아키텍처는 거대한 규모와 세계적인 범위를 다루기 위해 만들어졌다. Memcache 채택 당시, Facebook의 아키텍처는 다음 세 가지 주요 구성요소로 구성되었다.
1. Regions
Faceboook은 전략적으로 전 세계적으로 다양한 위치에 서버를 배치했고 이를 Region이라고 한다. 이 Region ㄷ르은 다음과 같은 두 가지 유형으로 분류된다.
- Primary Region: Primary Region은 대부분의 유저 트래픽과 데이터 관리를 담당한다.
- Secondary Region: 다수의 Secondary Region들은 중복도, 로드 밸런싱, 그리고 서로 다른 지역에 있는 사용자들의 퍼포먼스 향상을 제공하기 위해 전세계적으로 분산되어있다.
각 region (primary든 secondary 든)은 다수의 프론트엔드 클러스터와 하나의 스토리지 클러스터를 포함하고 있다.
2. Frontend Clusters
각 region에서 Facebook은 프론트엔드 클러스터를 유저의 요청과 서버 콘텐츠를 다루는데 사용했다. 프론트엔드 클러스터는 두 개의 메인 컴포넌트가 있다.
- Web Servers: 유저 요청 처리, 페이지 렌더링, 유저에게 컨텐츠 전달을 책임지고 있다.
- Memcache Servers: 분산된 캐싱 레이어의 역할을 하며 빠른 검색을 위해 자주 엑세스하는 데이터를 메모리에 저장한다.
프론트엔드 클러스터는 수요에 따라 확장될 수있도록 설계되어있다. 사용자 트래픽이 증가하면 증가된 부하를 처리하기 위해 추가적인 Web, Memcache 서버를 클러스터에 추가할 수 있다.
3. Storage Cluster
각 영역의 핵심에는 스토리지 클러스터가 있다. 이 클러스터는 Facebook의 시스템 내의 모든 데이터 항목의 복사본을 저장하는 Source of Truth 데이터베이스가 포함되어있다.
스토리지 클러스터는 데이터 일관성, 내구성, 신뢰성을 담당한다. 멀티 region간의 데이터 복제 및 primary-secondary 아키텍처를 적용하면서 Facebook은 높은 가용성과 내결함성을 달성한다.
아래 다이어그램을 확인해보자.

Facebook의 주요 철학 중 하나는 백엔드에 과도한 로드가 걸리는 것을 허용하는 대신에 약간 오래된 데이터(stale data)를 노출시키는 방식이다.
항상 완벽한 데이터 일관성을 위해 노력하는 대신, 유저는 피드에서 예전 정보를 가끔 볼 수도 있다는 사실을 받아들였다. 이런 접근 방식을 통해 백엔드 인프라에 과도한 부담을 주지도 않으면서 높은 트래픽 부하를 처리할 수 있게 되었다.
매일 수십억 개의 요청에 달하는 매우 큰 규모로 작동하도록 하기위해 Facebook은 아래와 같은 여러 과제들을 해결해야했다.
- 클러스터 내 지연 시간 및 장애 관리하기
- region간 데이터 복제 관리하기
- region간 데이터 일관성 관리하기
다음 부분에서 각 과제들을 어떻게 해결했는지 알아볼 것이다.
Within-Cluster Challenge
클러스터 내 운영에 대한 중요한 목표 세가지가 있다.
- 대기 시간(latency) 줄이기
- 데이터베이스 부하 줄이기
- 오류 처리하기
1. 대기시간(latency) 줄이기
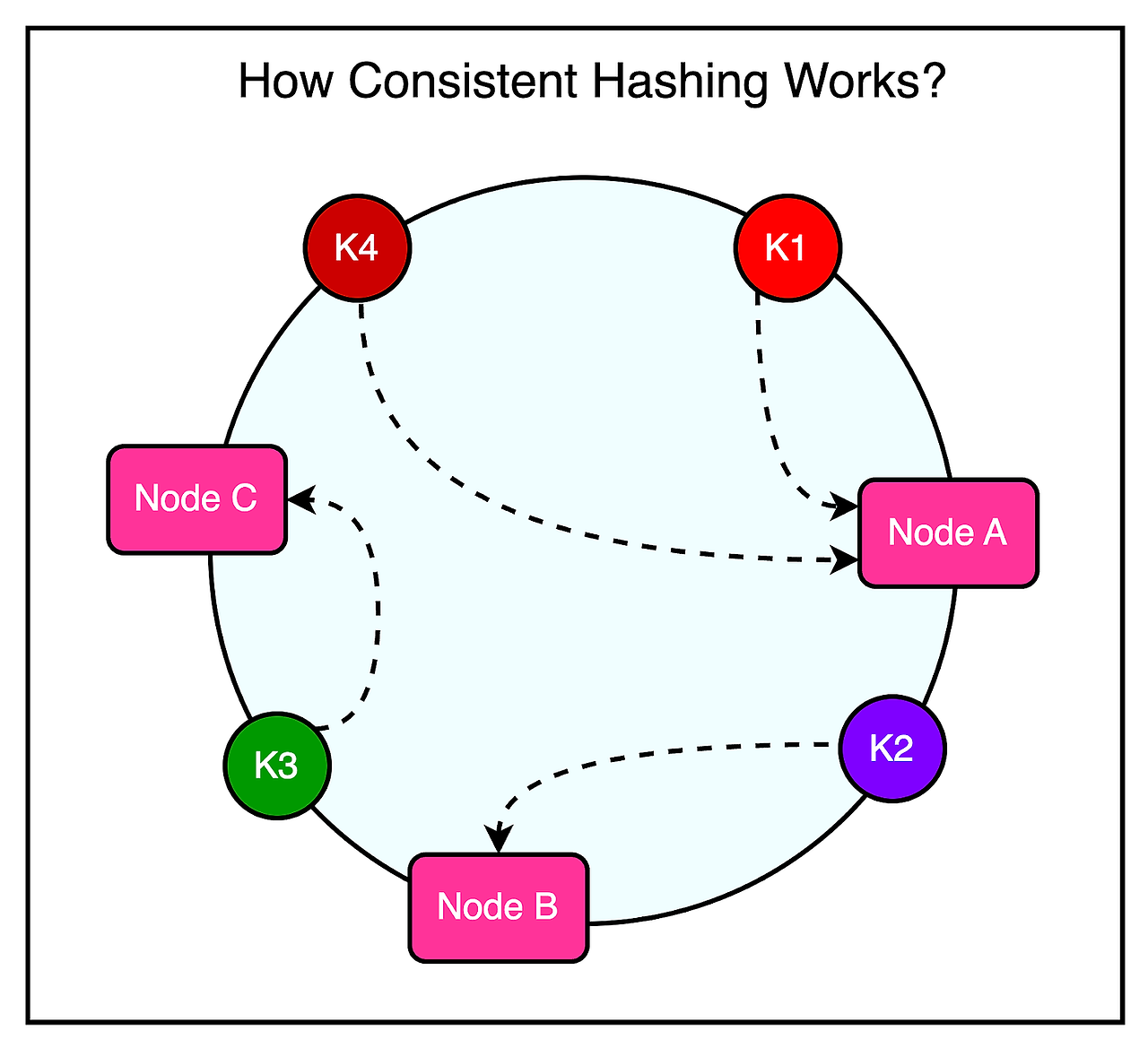
앞서 언급했듯이, 프론트엔드 클러스터는 수백개의 Memcached 서버를 포함하고 있고, 일관된 해싱(Consistent Hashing)과 같은 기술을 사용하여 이런 서버에 아이템들을 분산한다.
참고로 일관된 해싱(Consisten Hashing)은 노드 장애 또는 추가의 영향을 최소화하는 방식으로 여러 노드에 걸쳐 키 집합을 분배할 수 있도록 하는 기술이다. 노드가 다운되거나 새로운 노드가 추가되면, Consistent Hasing은 데이터의 완전한 재구성을 요구하는 것보단 키의 아주 작은 부분 집합만을 재분배되면 되도록 보장한다.
아래 그림은 키들이 원형 해시 공간에 매핑되고 노드가 원 위의 위치에 할당되는 Consisten Hashing의 컨셉을 보여준다. 각 키는 시계방향으로 가장 가까이에 있는 노드에 할당된다.
Facebook 규모에서는 하나의 웹 요청은 Memcached 서버로부터 데이터를 검색하기 위해 수백 개의 fetch 요청을 트리거할 수 있다. 사용자가 수많은 게시물과 댓글을 포함하는 인기 페이지를 로딩하는 시나리오를 생각해보자.
하나의 요청으로도 웹 서버가 필요한 데이터를 얻기위해 짧은 시간 내에 다수의 Memcached 서버와 통신할 수 있다.
이런 대용량 데이터 페치는 cache hit 상황뿐만 아니라 cache miss 상황에서도 발생할 수 있다. 여기서 주의해야할 점은 하나의 Memcached 서버가 여러 웹 서버의 병목 현상으로 연결되고, 사용자에게 지연 시간 증가 및 성능 저하를 안겨줄 수 있다는 점이다.
이런 시나리오의 가능성을 없애기 위해 Facebook은 아래와 같이 몇가지 중요한 트릭을 사용했다.
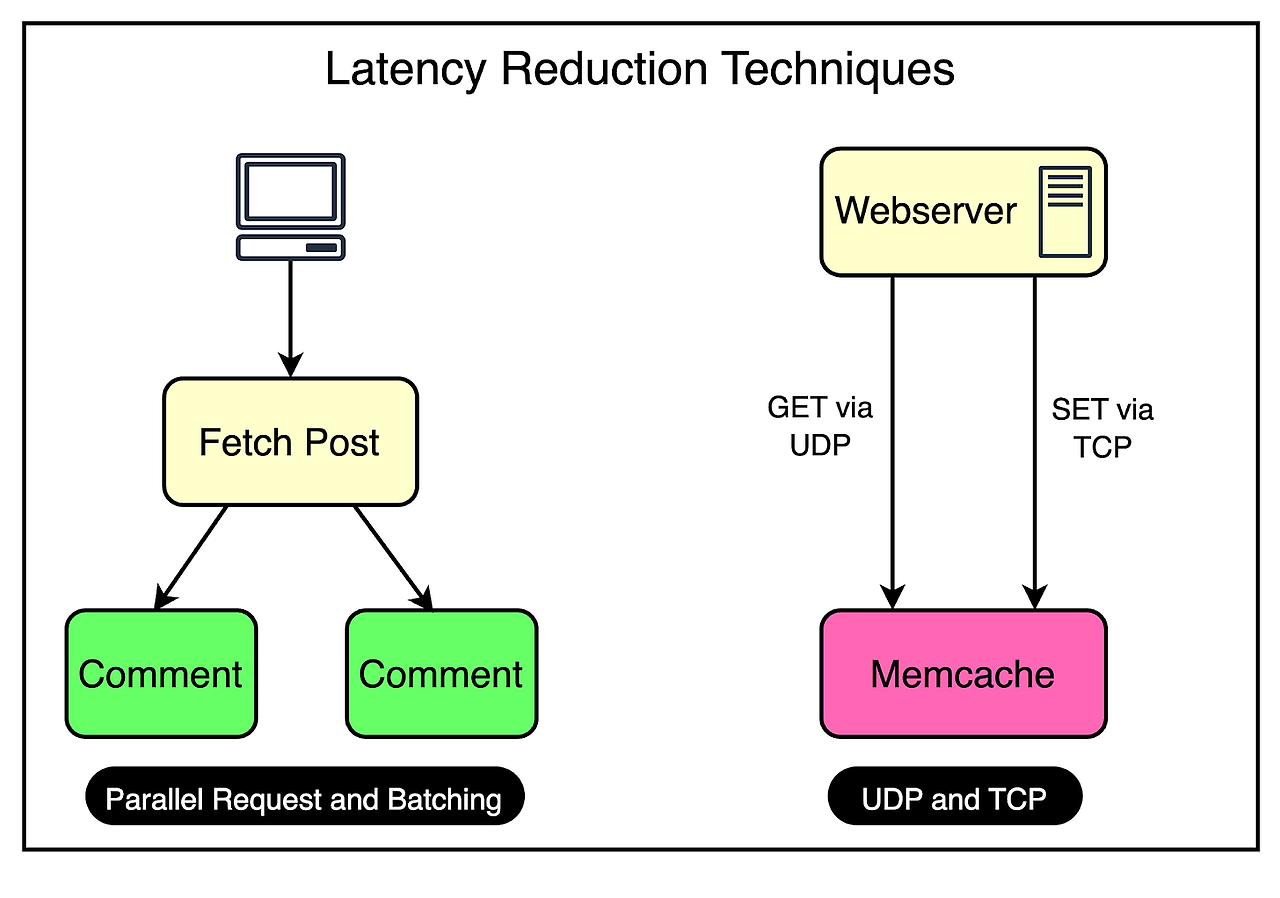
Parallel Requests and Batching - 병렬 요청 및 배치 작업
병렬 요청과 배치 작업의 컨셉을 이해하기 위해서 간단한 비유를 해보자.
물건이 필요할 때마다 마트에 간다고 상상해보자. 하나의 품목을 사기위해 여러번 마트에 방문하는 것은 시간이 많이 소요되며 비효율적이다. 대신, 한 번의 방문으로 여러 품목을 함께 구매하는 것이 훨씬 효과적이다.
Facebook의 프론트엔드 클러스터에도 이 원리가 적용되어 있다.
Facebook은 데이터 검색의 효율성을 극대화하기위해 서로 다른 데이터 항목 간의 종속성을 나타내는 DAG(Directed Acyclic Graph)를 구축했다. DAG는 어떤 데이터 항목을 동시에 가져올 수 있는지, 어떤 항목이 다른 항목에 의존하는지를 정확하게 알고있다.
DAG를 분석함으로써, 웹 서버는 데이터 fetching의 최적의 순서와 그룹화를 결정할 수 있다. 종속성없이 병렬로 검색할 수 있는 데이터 항목을 식별하여 하나의 배치 요청으로 그룹화한다.
UDP 사용하기
웹 서버와 Memcache 서버간의 네트워크 통신을 최적화하기위해 좋은 전략을 사용했다.
Fetch 요청에 한해, Facebook은 TCP대신 UDP 통신을 선택했다.
알다시피, UDP는 비연결성(connectionless) 프로토콜로 TCP보다 훨씬 빠르다. UDP를 사용함으로써, 클라이언트는 네트워크 오버헤드가 적은 Memcache 서버로 fetch 요청을 보내고 이는 더 빠른 요청 처리와 지연 시간을 줄일 수 있다.
하지만, UDP는 단점이 있다. 패킷 전달을 보장해주지 않는다. 전송 도중 패킷이 유실되면, UDP는 다시 전송하지 않는다.
이런 경우를 대응하기 위해, UDP 패킷 유실을 클라이언트의 cache miss로 간주했다. 만약 특정 시간 내에 응답이 도착하지 않으면, 클라이언트는 캐시로부터 데이터를 받을 수 없다고 판단하고, primary data source로 fetch 요청을 보낸다.
업데이트, 삭제 요청에 한해서는 올바른 순서로 패킷 전송을 보장해주는 TCP를 사용한다. 업데이트 및 삭제 작업을 처리할 때 중요한 특정 재시도 매커니즘을 추가하지 않아도 된다.
이 모든 요청은 웹서버와 동일한 시스템에서 동작하는 mcrouter 라는 프록시를 거친다. mcrouter를 데이터 직렬화, 압축, 라우팅, 일괄 처리, 에러 처리와 같은 여러 가지 임무를 하는 중간 수행자라고 생각하면 된다. mcrouter는 다음 섹션에서 살펴보자.
2. 데이터베이스 부하 줄이기
Memcache의 가장 중요한 목적은 데이터베이스에 데이터를 가져오는 빈도를 줄임으로써 데이터베이스 부하를 줄이는 것이다.
Memcache를 look-aside 캐시로 사용하면 이 문제를 대부분 해결할 수 있다. 하지만 Facebook 규모에서는 두 가지 문제가 자주 발생할 수 있다.
- Stale Set: 캐시가 오래된 데이터로 설정되어 있고, 캐시를 무효화할 수 있는 쉬운 방법이 없는 경우에 발생
- Thundering Herd: cache miss가 데이터베이스에 수많은 요청을 트리거할 때 동시적인 환경에서 발생
아래 그림은 이 이슈들을 시각화한 것이다.
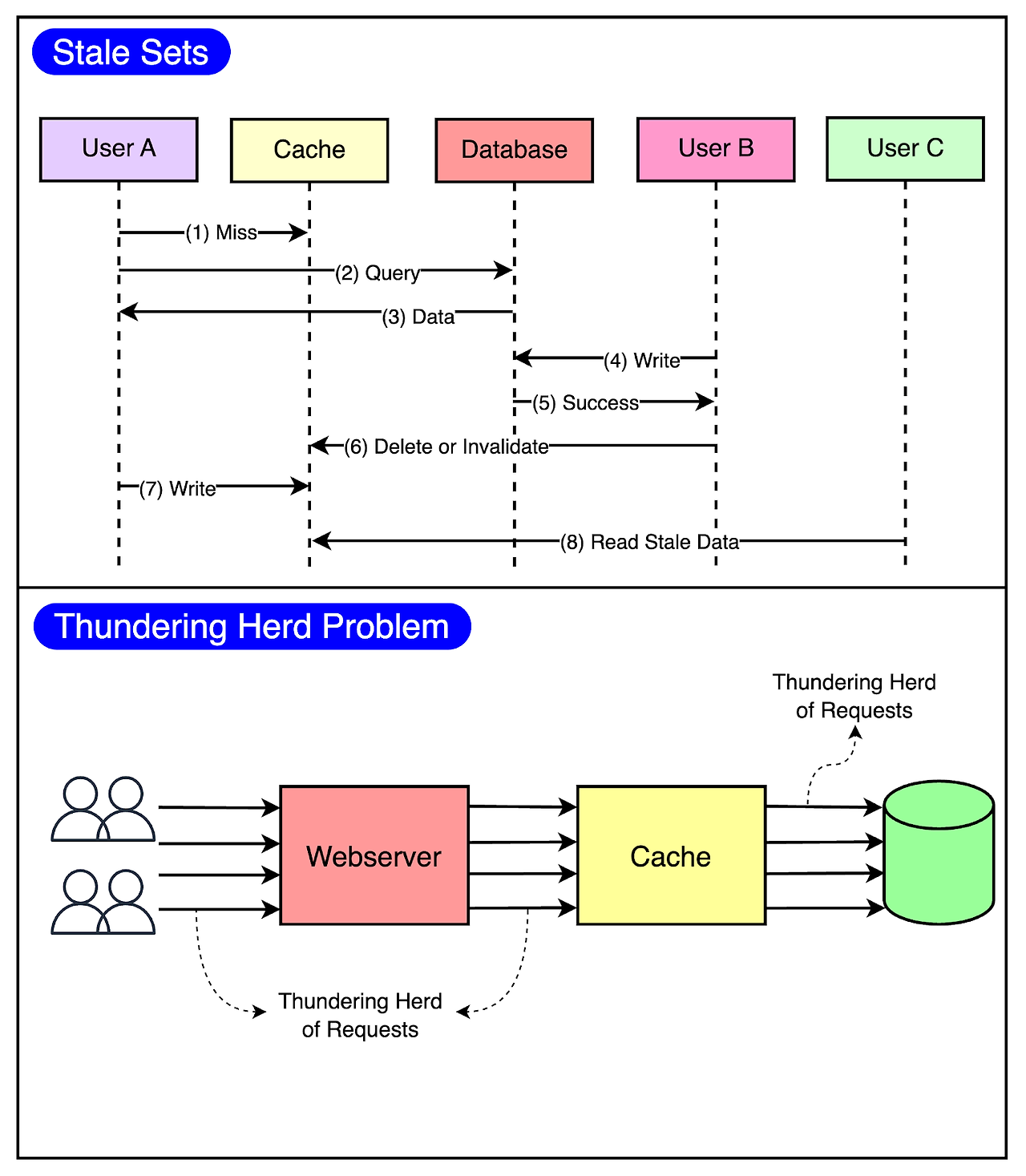
이 두 가지 중요한 문제가 발생할 가능성을 최소화하기 위해 Leasing이라는 기술을 사용했다. Leasing은 statle set과 thundering herds 모두 해결해줬으며, DB 쿼리 속도를 초당 17K에서 1.3K로 단축시켰다.
Stale Sets
클라이언트가 특정 키로 memcache에 요청을 보냈는데, cache miss가 발생했다고 생각해보자.
이때, 데이터베이스로부터 데이터를 가져오는 것은 클라이언트가 해야하며, 동일한 키로 cache miss가 재발하지 않도록 memcache를 업데이트해줘야한다.
대부분의 경우 잘 동작하지만, 매우 동시적인 환경에서는 클라이언트가 설정하는 데이터가 캐시에 업데이트되기전까지는 오래된 데이터가 되어버린다.
Leasing은 이걸 막아준다.
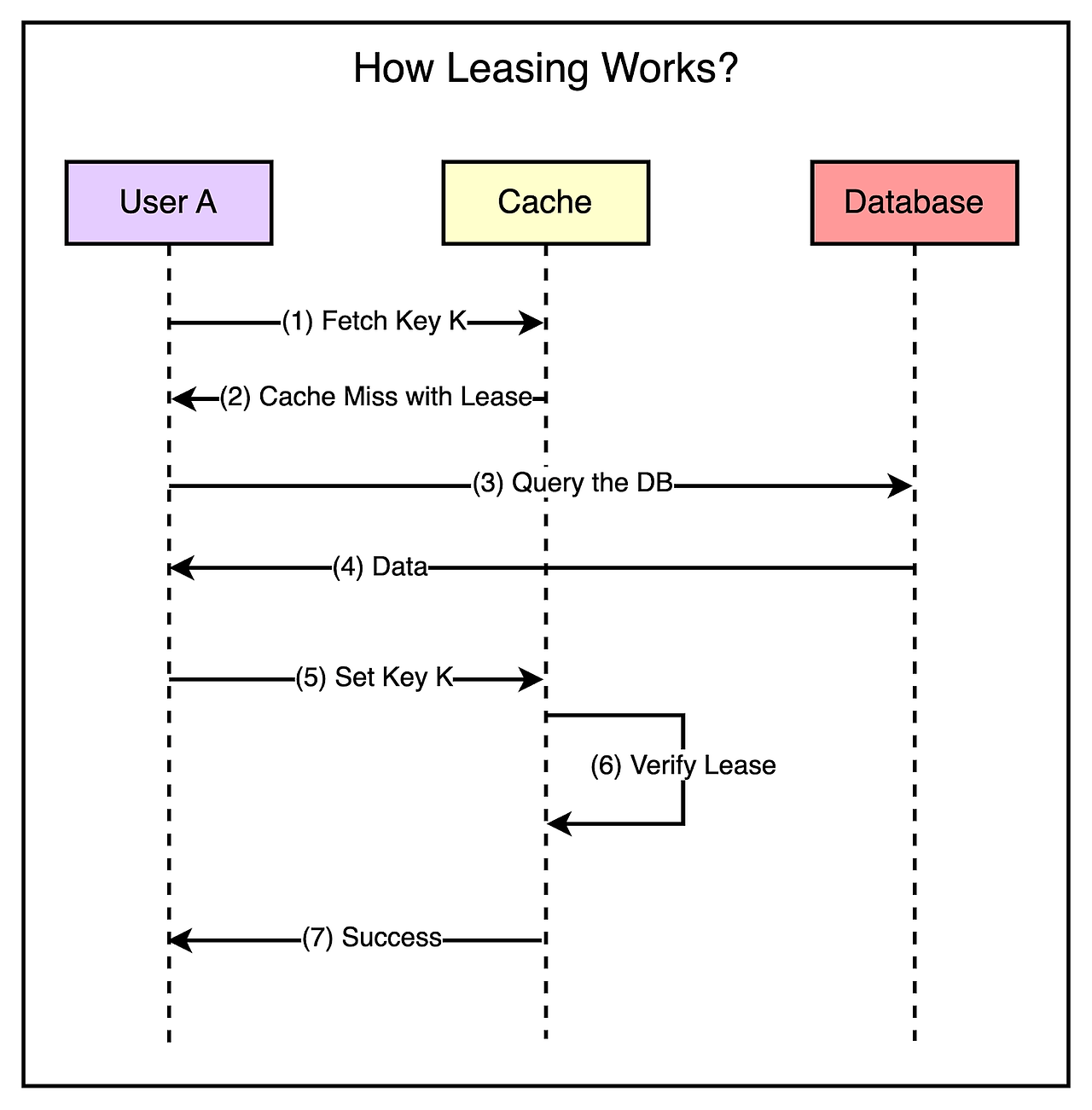
Leasing를 통해 Memcache는 cache miss가 발생할 때마다 데이터를 캐시에 설정하기 위해 lease(특정 키에 바인딩된 64bit 토큰)를 특정 클라이언트에게 전달한다.
클라이언트는 캐시에 값을 업데이트할 때, 해당 토큰을 제시해야하며, memcache는 토큰 유효성 검증을 통해 데이터가 저장되어야하는지 여부를 확인할 수 있다. 클라이언트가 업데이트하려는 시점에 이미 데이터가 유효하지 않다면, Memcache는 lease 토큰을 비활성화시키고, 요청을 거부한다.
아래 그림은 leasing의 컨셉을 조금 더 자세히 보여준다.
Thundering Herds
leasing에 약간의 수정을 통해 thundering herds 문제도 해결할 수 있다.
Memcache는 lease 토큰 발행 비율을 규제한다. 예를 들어, 키마다 5초에 한 번씩 토큰을 반환할 수 있다.
lease 토큰이 발행된 후 5초 내에 키에 대한 요청이 있을 경우, Memcache는 이 요청으로 인해 데이터베이스에 불필요한 타격을 주지 않도록 클라이언트에게 대기 후 재시도하라는 응답을 보낸다.lease token을 가진 클라이언트가 잠시 대기 후 캐시를 업데이트할 것이고, 이를 기다리는 클라이언트는 높은 확률로 cache hit을 얻게될 것이기 때문이다.
* Cache hit: 캐시 메모리에 해당 데이터 가지고 있음
* Cache miss: 캐시 메모리에 해당 데이터가 없어서 다른 곳에서 가져와야하는 상황
3. 오류 처리하기
Facebook과 같은 대규모에서는 에러는 항상 발생할 수밖에 없다.
수백만 명의 사용자가 플랫폼을 사용하는 상황에서 Memcache에서 데이터 검색에 차질이 생기면 심각한 문제를 일으킨다. Memcache로부터 데이터를 가져오지 못한다면, 백엔드 서버에 엄청난 부하를 일으키게 되고, 여러 다운스트림 서비스들에 cascading failure가 발생할 가능성이 커진다.
Two Levels of Failure
Facebook은 Memcache를 사용하면서 두가지 중요한 이슈를 겪었다.
- Small-Scale Outages: 네크워크 문제나 기타 로컬 문제로 인해 일부 호스트에서 엑세스 할 수 없게 될 수도 있다. 이러한 중단은 범위가 제한적이지만 전체 시스템 성능에 영향을 미칠 수 있다.
- Widespread Outages: 조금 더 심각한 경우를 보자면, 클러스터가 다운되어 상당 비율의 Memcache 호스트에 영향을 줄 수 있다. 이런 광범위한 중단은 시스템의 안정성과 가용성에 더 큰 위협이 된다.
Widespread Outages 다루기
Facebook은 클러스터 다운의 영향을 완화하기위해 웹 요청을 다른 기능 클러스터로 전환했다. 부하를 재분배하여 문제가 있는 클러스터가 건강을 회복할 수 있을 때까지 책임에서 벗어나게 한다.
Small Outages 자동 복구
소규모 outages의 경우, Facebook은 영향을 받는 인스턴스를 대체할 새로운 인스턴스를 생성하여 호스트 수준의 문제를 자동으로 감지하고 대응하는 자동 복구 시스템에 의존하고있다.
하지만 복구 프로세스가 즉각적이지않고 간혹 복구하는데 시간이 소요된다. 이 시간동안 백엔드 서비스들은 클라이언트들이 이용하지 못하는 Memecache hosts로부터 데이터를 가져오려고 시도할 때 요청이 급증하는 것을 경험할 수 있다.
이때 보편적인 방법으로는, key를 다시 해싱하고, 남은 서버에 분산하는 것이다.
하지만 Facebook 개발팀은 해당 방식도 여전히 연쇄적으로 실패하기 쉽다는 것을 깨달았다. 그들의 시스템에서는 많은 키들이 하나의 서버에 대한 요청의 상당 부분(거의 20%)을 차지할 수 있다. 장애 시나리오동안 트래픽이 많은 키들을 다른 서버로 이동하면 과부하가 발생하고 더 불안정해질 수 있다.
이런 위험을 줄이기 위해, Gutter machine을 도입했다. 각 클러스터에서 Gutter machine으로 특별히 지정된 machine pool(일반적으로 Memcache 서버의 1%)을 할당했다. outage가 발생했을 때, Memcache 서버의 책임을 대신하도록 설계되었다.
어떻게 동작하는지 확인해보자.
- Memcache 클라이언트가 응답을 못 받았다면(cache miss도 아니다), 클라이언트는 서버에 장애가 생겼다고 가정하고 Gutter pool에 요청을 보낸다.
- 만약, Gutter pool이 cache miss를 반환하면 클라이언트는 데이터베이스를 쿼리하고, Gutter pool에 데이터를 추가하여 Memcache로부터 후속 요청을 받을 수 있다.
- Gutter 엔트리는 캐시 무효화의 필요성을 제거하기 위해 빠르게 만료된다.
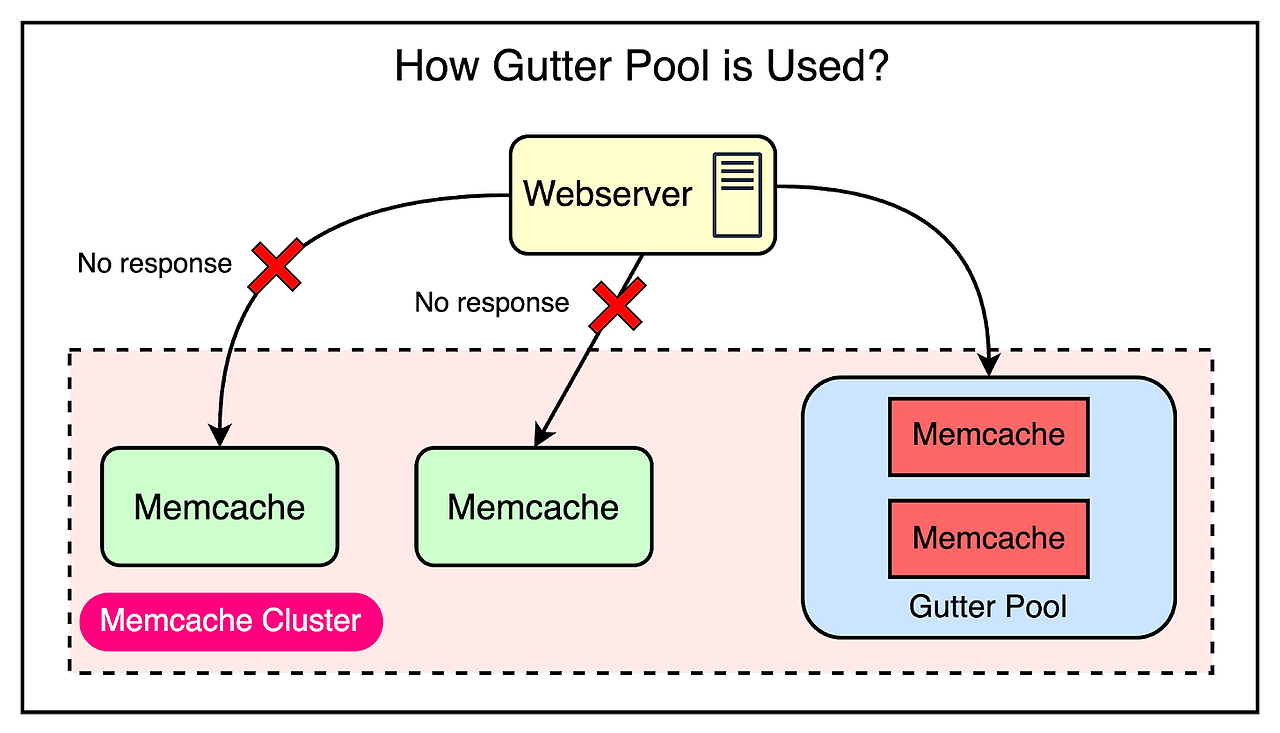
오래된 데이터(stale data)를 제공할 가능성은 있지만, 백엔드는 보호된다. 가용성과 비교하여 이 방법은 허용할만한 절충안이었다는 것을 기억하자.
Region Level Challenges
Region level에서는 여러 개의 프론트엔드 클러스터를 처리해야했고, 주요 과제는 모든 클러스터에서 Memcache 무효화를 처리하는 것이었다.
로드밸런서에 따라, 사용자가 데이터를 요청할 때 서로 다른 프론트엔드 클러스터에 연결할 수 있다. 이로 인해 특정 데이터 조각이 여러 클러스터에 캐싱된다.
즉, 특정 키가 region 내 여러 클러스터의 Memcache 서버에 캐시되는 시나리오를 가질 수 있다. 아래 그림은 이 시나리오에 대해서 설명해준다.
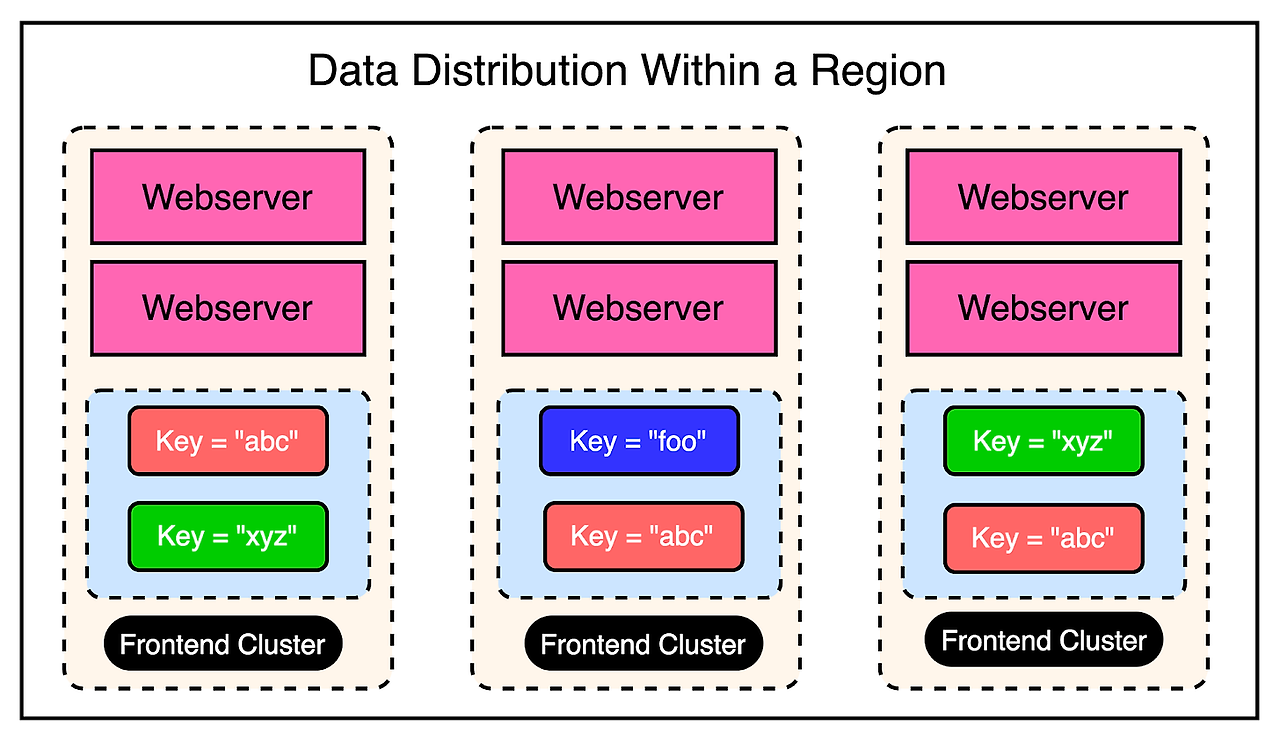
예를 들어, key 'abc', 'xyz'는 region 내 다수의 프론트엔드 클러스터에 존재하고, 이 값을 업데이트할 경우 무효화되어야 한다.
Cluster Level Invalidation
클러스터 레벨에서 데이터를 무효화하는 것이 더 간단하다. 데이터를 수정하는 어느 웹 서버에서 해당 클러스터에 있는 데이터를 무효화시킬 책임을 갖고 있다. 이를 통해 요청을 보낸 사용자에게 쓰기 후 읽기 일관성(read-after-write consistency)을 제공할 수 있다. 클러스터 내에서 오래된 데이터의 수명을 줄여준다.
참고로 쓰기 후 읽기 일관성(read-after-write consistency)은 사용자가 일부 업데이트를 하면 페이지가 다시 로드될 때 업데이트내역을 항상 볼 수 있도록 보장하는 것이다.
Region Level Invalidation
Region 레벨 무효화는, 무효화 과정이 조금 더 복잡하며 웹 서버가 처리하지 않는다.
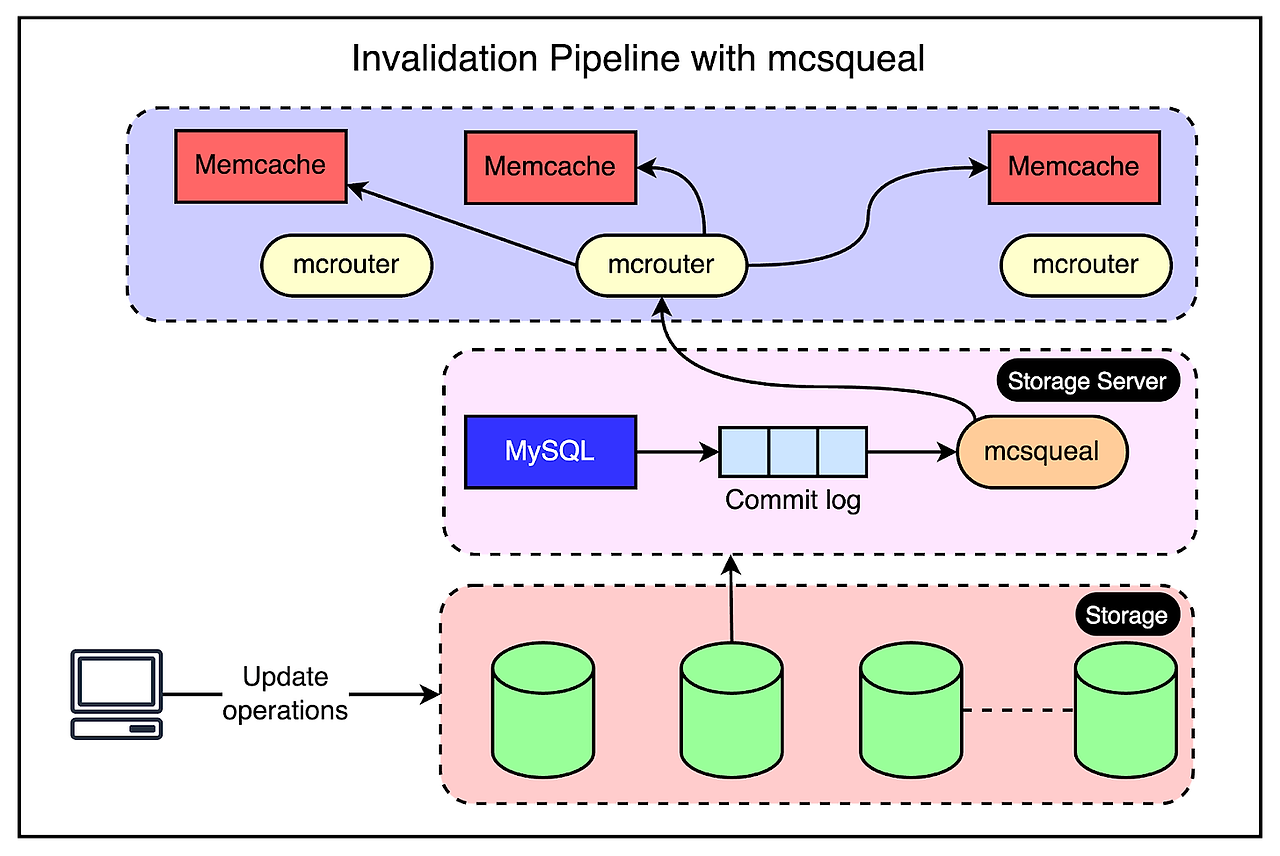
대신, Facebook은 비슷한 일을 하는 무효화 파이프라인을 만들었다.
- mcsqueal로 알려진 무효화 데몬은 스토리지 클러스터 내의 모든 데이터베이스 서버에서 실행된다.
- 이 데몬은 커밋 로그를 확인하여 모든 삭제 내역을 뽑아 region 내 모든 프론트엔드 클러스터에 있는 Memcache deployments에 브로드캐스팅한다.
- 성능을 위해 mcsqueal은 더 작은 패킷으로 삭제 작업을 배치하고, 각 클러스터의 mcrouter 인스턴스를 실행하는 전용 서버로 전송한다.
- mcrouter 인스턴스는 배치 내의 각각의 삭제 작업을 반복하며 올바른 Memcache 서버로 보내준다.
아래 그림을 확인해보자.
Challenges with Global Regions
Facebook 규모로 운영하려면 전 세계적으로 데이터 센터를 운영하고 유지해야 한다.
하지만, 여러 지역으로 확대하는 것도 여러 가지 도전이 필요하다. 가장 큰 문제는 Memcache의 데이터와 region 간의 지속적인 스토리지 간의 일관성을 유지하는 것이다.
Facebook의 region 설정에서는, 한 region이 주요 데이터베이스를 보유하고 있고, 다른 지리적 region은 읽기 전용 복제본을 포함하고있다. 복제본은 MySQL 복제 메커니즘을 이용하여 primary DB와 동기화된 상태로 유지된다.
하지만 복제를 하게되면, 복제 지연(replciation lag)이 발생할 수 밖에 없다. 즉, 복제 데이터베이스는 primary 데이터베이스보다 뒤쳐질수 밖에 없다.
일관성을 위해 크게 두 가지 경우를 고려해야한다.
Primary Region에서 쓰기
primary region(US)에 있는 웹서버가 사용자로부터 프로필 사진 업데이트 요청을 받았다고 가정해보자.
일관성을 유지하기 위해, 다른 region에도 변화가 전파될 필요가 있다.
- Replica 데이터베이스는 업데이트되어야 하낟.
- Secondary Region의 Memcache 인스턴스를 무효화해야 한다.
복제와 함께 무효화를 관리하는 것이 어렵다.
실제 변경 사항이 Region(US)에 복제되기 전에, Secondary Region(유럽)에 도달할 경우 아래와 같은 race condition이 발생할 수도 있다.
- Europe region에 있는 누군가가 프로필 사진을 조회한다.
- 캐시로부터 정보를 요청하지만, 무효화되었다.
- Europe Region의 읽기 전용 데이터베이스로부터 뒤떨어진(lagging) 데이터를 가져온다. 즉, 예전 사진을 가져와서 캐시에 설정한다는 뜻이다.
- 결국 replication은 성공했으나, 캐시가 과거 데이터(stale data)로 설정되었고 추후 요청들은 캐시로부터 과거 데이터를 가져오게 된다.
해당 시나리오를 그림으로 표현해보았다.
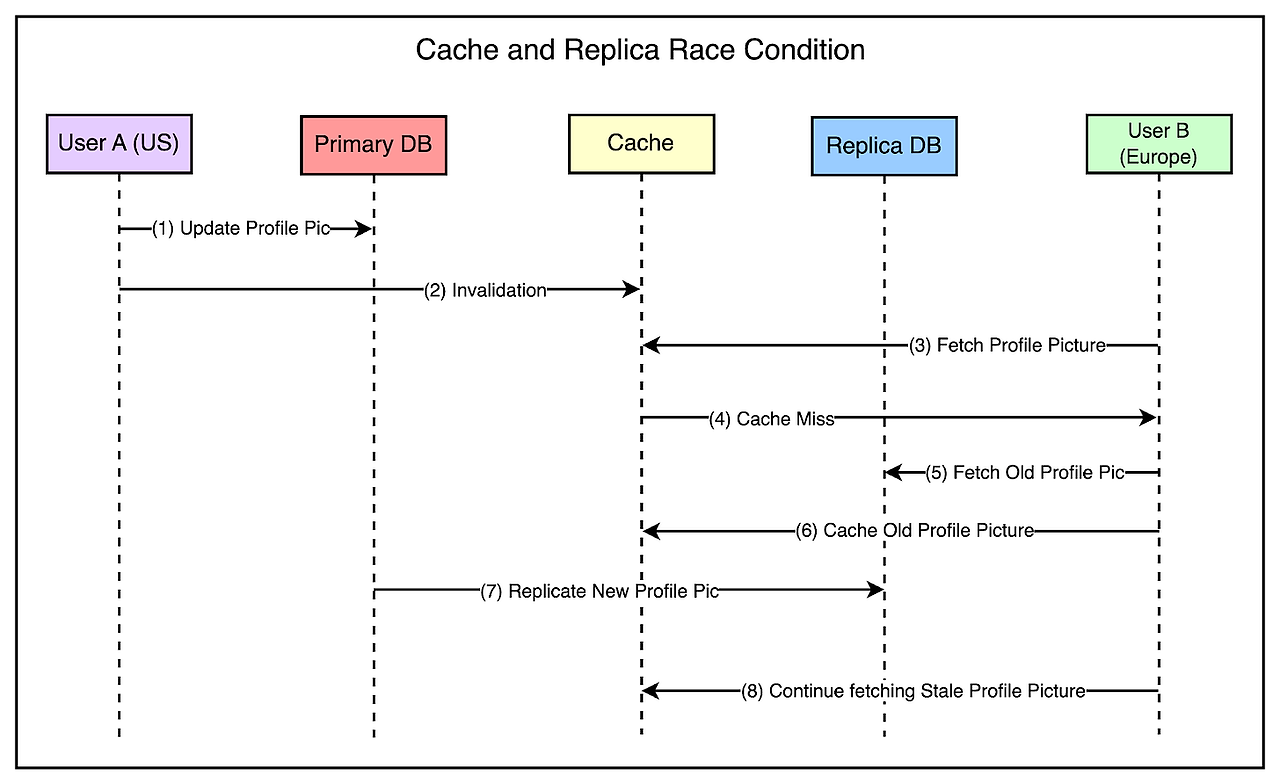
이런 race condition을 피하기 위해, Facebook은 최신 정보를 가진 스토리지 클러스터가 region 내에서 무효화를 전송할 책임이 있도록 구현했다. 이전 섹션에서 이야기한 것과 동일한 mcsqueal 설정을 사용한다.
이 접근 방식을 사용하면 데이터베이스에서 변경사항이 완전히 복제되기 전에 무효화가 복제본 영역으로 조기에 전송되지 않는다.
Non-Primary Region에서 쓰기
non-primary region에서 비롯된 쓰기를 다룰 때 이벤트 순서는 다음과 같다.
- 사용자는 secondary region에서 프로필 사진을 변경한다. 복제나 secondary region에서 읽기가 진행될 때, 쓰기는 primary region에서 실행된다.
- write가 성공적으로 실행되면, secondary region에서도 변경사항이 반영되어야 한다.
- 하지만, replication에도 반영되기 전에 replica region에서 읽기 요청이 Memcache로 부터 캐시된 과거 데이터를 가져올 수도 있다.
Facebook은 이런 문제를 해결하기 위해 원격 마커(remote marker)라는 개념을 도입했다.
원격 마커는 로컬 복제본의 데이터가 잠재적으로 오래되었는지 여부를 나타내는 데 사용되며 primary region에서 쿼리되어야 한다.
아래처럼 동작한다.
- 클라이언트 웹서버가 키 K에 대한 데이터 업데이트를 요청하면, replica region에서 해당 키에 대한 원격 마커 R을 설정한다.
- 그다음, primary region에서 쓰기를 진행한다.
- 키 K는 replica region의 Memcache 서버에서 제거된다.
- replica region의 키 K에 대한 읽기 요청이 들어오지만 웹 서버는 캐시를 놓치게 된다.
- 원격 마커 R이 존재하는지 확인하고, 만약 있다면 primary region에 바로 쿼리된다.
아래 그림을 확인해보자.
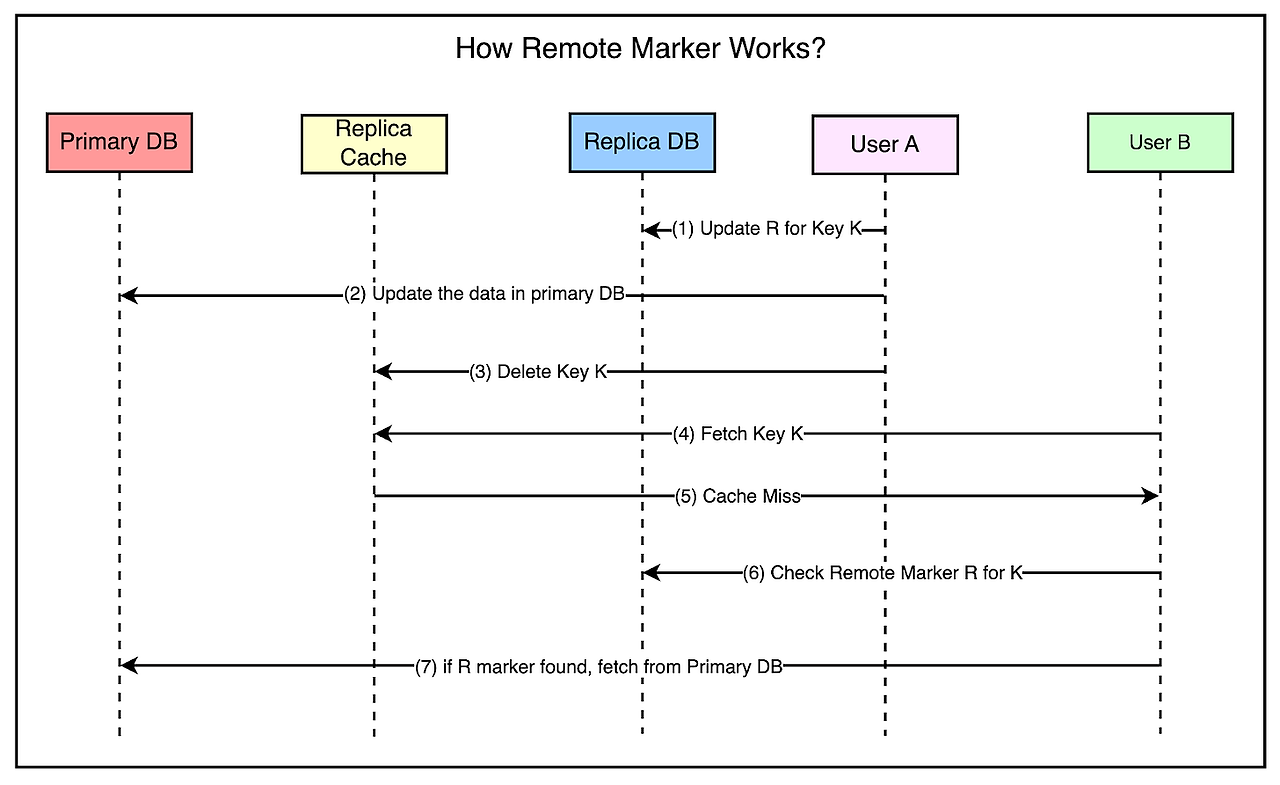
캐시를 우선 확인하고, 원격 마커도 확인한 후에 primary region에 쿼리하기때문에 이 방법이 비효율적이라고 생각할 수도 있다.
위 시나리오에서 Facebook은 과거 데이터를 읽을 확률을 줄이는 대신 cache miss의 지연 시간(latency)와 교환하기로 결정했다.
단일 서버 최적화
보다시피 Facebook은 Memcache의 요구 사항을 확장하기 위해 몇 가지 중요한 아키텍처 결정을 했다. 그러나 개별 Memcache 서버의 성능을 최적화하는데 상당한 시간을 소비했다.
이런 개선은 단독으로는 작게 보일 수 있지만, Facebook 규모에서의 누적되는 영향력은 상당했다. 몇가지 중요한 최적화 방식에 대해 알아보자.
자동 해시 테이블 확장
저장 항목 수가 증가함에 따라, 해시 테이블에서 lookup 시간 복잡도는 테이블 크기가 고정된 상태로 유지될 경우 O(n)으로 떨어질 수 있다. 이러 인해 성능이 저하된다.
Facebook은 해시 테이블에 대한 자동 확장 매커니즘을 구현했다. 항목 수가 특정 임계값에 도달하면 해시 테이블은 자동으로 크기가 두 배로 증가하여 테이트 세트가 증가하더라도 lookup의 시간 복잡성이 일정하게 유지되도록 보장한다.
멀티 스레드 서버 아키텍처
단일 스레드에서 많은 양의 요청을 처리하면 지연 시간이 증가하고 처리량이 감소할 수 있다. 이를 해결하기 위해 멀티 스레드를 지원하고, 동시에 여러 요청을 처리할 수 있도록 Memcache 서버를 강화했다.
각 스레드에 대한 전용 UDP 포트
멀티 스레드가 동일한 UDP 포트를 공유하면 경합이 발생하여 성능 문제가 발생할 수 있다. 그들은 스레드들이 더 효율적으로 작동할 수 있도록 각각의 스레드들이 고유의 전용 UDP 포트를 갖도록 구현했다.
적응형(Adaptive) Slab Allocator
비효율적인 메모리 할당 및 관리는 단편화, 최적이 아닌 시스템 자원 활용으로 이어질 수 있다.
Facebook은 각 Memcache 서버 내의 메모리 구성을 최적화하기 위해 적응형 slab allocator를 구현했다. slab allocator는 사용 가능한 메모리를 슬랩(slab)이라는 고정된 크기의 청크로 나눈다.
Allocator는 메모리 활용도를 최대화하기위해 관찰된 요청 패턴에 기반하여 슬랩 크기를 동적으로 적응시킨다.
결론
Facebook의 Memcache 확장 여정은 개발자와 엔지니어에게 훌륭한 사례이다. 방대한 양의 데이터를 처리하고 수십억 명의 사용자에게 서비스를 제공해야 하는 전 세계적으로 분산된 SNS를 구축할 때 발생하는 문제를 강조한다.
Memcache를 구현하고 최적화함으로써, Facebook은 여러 수준에서 확장성 문제를 해결하는 것이 중요하다는 것을 보여준다. 높은 수준의 아키텍처 결정부터 낮은 수준의 서버 최적화에 이르기까지 모든 측면이 시스템 성능, 신뢰성, 효율성을 보장하는데 중요한 역할을 한다.
스터디로부터 아래 3개의 개념을 기억해두자.
- 궁극적인 일관성을 수용하는 것이 성능과 가용성의 핵심이다. 하지만, 모든 결정은 절충안에 대한 이해를 바탕으로 이루어져야 한다.
- 실패는 피할 수 없는 일이며 실패에 대비한 설계가 매우 중요하다.
- 최적화는 다양한 레벨에서 수행할 수 있다.
참고 자료
- Scaling Memcache at Facebook
- Facebook and Memcached
- Memcache FAQ by MIT
- Thundering Herd
- Cache-Aside Pattern
'Programming > System Design' 카테고리의 다른 글
| 메세지 브로커: In-Memory vs Log-Based (4) | 2024.09.22 |
|---|
